
Cómo probar un archivo Robots.txt usando SEO Spider
Se utiliza un archivo robots.txt para dar instrucciones a los robots sobre qué URL se pueden rastrear en un sitio web. Todos los bots de los principales motores de búsqueda se ajustan al estándar de exclusión de robots y leerán y obedecerán las instrucciones del archivo robots.txt antes de obtener cualquier otra URL del sitio web.
Los comandos se pueden configurar para que se apliquen a robots específicos de acuerdo con su agente de usuario (como ‘Googlebot’), y la directiva más común que se usa dentro de un archivo robots.txt es ‘no permitir’, que le dice al robot que no acceda a una URL. sendero.

Puede ver los robots.txt de un sitio en un navegador, simplemente agregando /robots.txt al final del subdominio (www.screamingfrog.co.uk/robots.txt, por ejemplo).
Si bien los archivos robots.txt son generalmente bastante simples de interpretar, cuando hay muchas líneas, agentes de usuario, directivas y miles de páginas, puede ser difícil identificar qué URL están bloqueadas y cuáles se pueden rastrear. Obviamente, las consecuencias de bloquear URL por error pueden tener un gran impacto en la visibilidad en los resultados de búsqueda.
Aquí es donde un probador de robots.txt como Screaming Frog y es robots.txt personalizados La característica puede ayudar a verificar y validar los robots.txt de un sitio a fondo y a escala.

En primer lugar, tendrá que descargar Screaming Frog que es gratis en formato lite, para rastrear hasta 500 URL. Cuanto más avanzado robots.txt personalizados funcionalidad requiere una licencia.
Puede seguir los pasos a continuación para probar el archivo robots.txt de un sitio que ya está activo. Si desea probar las directivas de robots.txt que aún no están activas o la sintaxis de comandos individuales para robots, lea más sobre la funcionalidad personalizada de robots.txt en sección 3 de nuestra guía.
1) Rastrear la URL o el sitio web
Abra SEO Spider, escriba o copie el sitio que desea rastrear en el cuadro ‘ingresar url a spider’ y presione ‘Iniciar’.
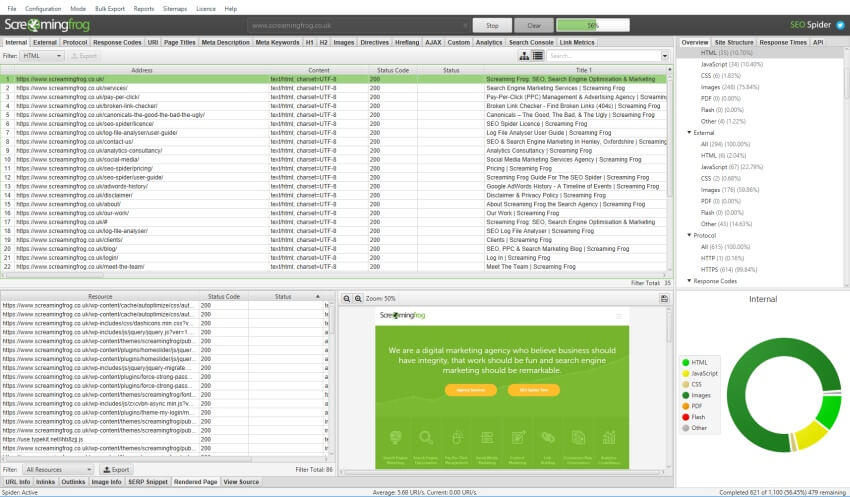
Si prefiere probar varias URL o un mapa del sitio XML, simplemente puede cargarlos en modo de lista (en ‘modo > lista’ en la navegación de nivel superior).

2) Ver la pestaña ‘Códigos de respuesta’ y el filtro ‘Bloqueado por Robots.txt’
Las URL no permitidas aparecerán con un ‘estado’ como ‘Bloqueado por Robots.txt’ en el filtro ‘Bloqueado por Robots.txt’.

El filtro «Bloqueado por Robots.txt» también muestra una columna «Línea de Robots.txt coincidente», que proporciona el número de línea y la ruta de rechazo de la entrada de robots.txt que excluye cada URL en el rastreo.
Las páginas de origen que se vinculan a URL que no están permitidas en robots.txt se pueden ver haciendo clic en la pestaña ‘enlaces’, que llena el panel inferior de la ventana.
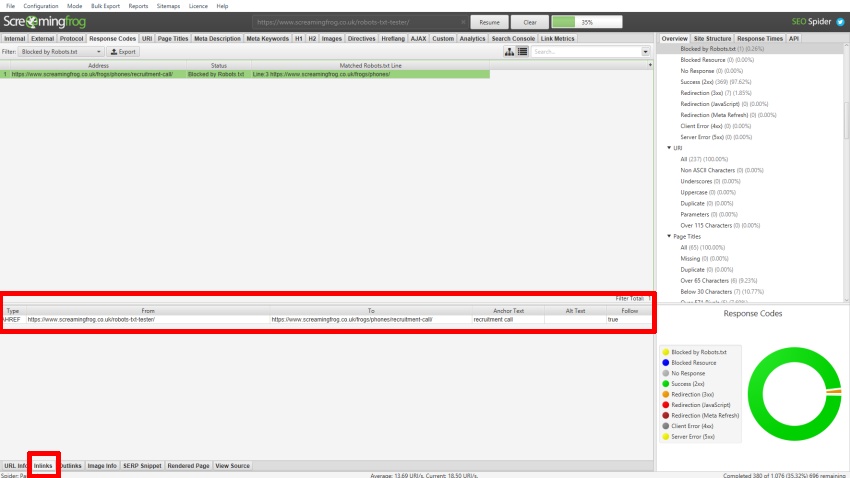
Aquí hay una vista más cercana del panel de la ventana inferior que detalla los datos de ‘enlaces’:

También se pueden exportar de forma masiva a través del informe ‘Exportación masiva > Códigos de respuesta > Bloqueados por Robots.txt Inlinks’.

3) Prueba usando el Custom Robots.txt
Con un licenciatambién puede descargar, editar y probar el archivo robots.txt de un sitio mediante el robots.txt personalizados en ‘Configuración > robots.txt > Personalizado’.
La función le permite agregar múltiples robots.txt a nivel de subdominio, probar directivas en SEO Spider y ver las URL que están bloqueadas o permitidas de inmediato.
También puede realizar un rastreo y filtrar las URL bloqueadas según el archivo robots.txt personalizado actualizado (‘Códigos de respuesta > Bloqueado por robots.txt’) y ver la línea de directiva de robots.txt coincidente.

El archivo robots.txt personalizado utiliza el seleccionado agente de usuario en la configuración, que se puede modificar para probar y validar cualquier robot de búsqueda.
Tenga en cuenta: los cambios que realice en el archivo robots.txt dentro de SEO Spider no afectan a su archivo robots.txt en vivo cargado en su servidor. Sin embargo, cuando esté satisfecho con las pruebas, puede copiar los contenidos en el entorno en vivo.
Cómo la araña SEO obedece a Robots.txt
los Gritando Rana SEO Spider obedece a robots.txt de la misma manera que Google. Verificará el archivo robots.txt de los subdominios y seguirá las directivas (permitir/no permitir) específicamente para el agente de usuario ‘Screaming Frog SEO Spider’, si no Googlebot y luego TODOS los robots.
Las URL que no están permitidas en robots.txt seguirán apareciendo y se ‘indexarán’ dentro de la interfaz de usuario con un ‘estado’ como ‘Bloqueado por Robots.txt’, simplemente no se rastrearán, por lo que el contenido y los enlaces externos de la página no se verá Mostrar enlaces internos o externos bloqueados por robots.txt en la interfaz de usuario se puede desactivar en el configuración de robots.txt.
Es importante recordar que las URL bloqueadas en robots.txt aún se pueden indexar en los motores de búsqueda si están vinculadas interna o externamente. Un archivo robots.txt simplemente evita que los motores de búsqueda vean el contenido de la página. Una metaetiqueta ‘noindex’ (o X-Robots-Tag) es una mejor opción para eliminar contenido del índice.
La herramienta admite la coincidencia de URL de valores de archivo (comodines * / $), al igual que Googlebot, también.
Ejemplos comunes de Robots.txt
Una estrella junto al comando ‘User-agent’ (User-agent: *) indica que las directivas se aplican a TODOS los robots, mientras que los bots User-agent específicos también se pueden usar para comandos específicos (como User-agent: Googlebot).
Si los comandos se usan tanto para todos como para agentes de usuario específicos, el bot de agente de usuario específico ignorará los comandos ‘todos’ y solo se obedecerán sus propias directivas. Si desea que se obedezcan las directivas globales, también deberá incluir esas líneas en la sección específica del agente de usuario.
A continuación se muestran algunos ejemplos comunes de directivas utilizadas en robots.txt.
Bloquear todos los robots de todas las URL
Agente de usuario: *
No permitir: /
Bloquear todos los robots de una carpeta
Agente de usuario: *
No permitir: /carpeta/
Bloquear todos los robots desde una URL
Agente de usuario: *
No permitir: /una-url-específica.html
Bloquear Googlebot de todas las URL
Agente de usuario: robot de Google
No permitir: /
Bloquear y permitir comandos juntos
Agente de usuario: robot de Google
No permitir: /
Permitir: /rastrear-esto/
Si tiene directivas en conflicto (es decir, un permiso y un rechazo en la misma ruta de archivo), entonces una directiva de permiso coincidente supera a una denegación coincidente cuando contiene el mismo número de caracteres o más en el comando.
Coincidencia de comodín de URL de robots.txt
Google y Bing permiten el uso de comodines en robots.txt. Por ejemplo, para bloquear el acceso de todos los rastreadores a todas las URL que incluyan un signo de interrogación (?).
Agente de usuario: *
No permitir: /*?
Puede utilizar el carácter de dólar ($) para que coincida con el final de la URL. Por ejemplo, para bloquear el acceso de todos los rastreadores a la extensión de archivo .html.
Agente de usuario: *
No permitir: /*.html$
Puede obtener más información sobre los valores de ruta basados en la coincidencia de URL en Especificaciones de robots.txt de Google guía.
Si tiene más preguntas sobre cómo usar el probador de robots.txt dentro de Screaming Frog entonces por favor póngase en contacto con nuestro apoyo equipo.