
Cómo encontrar contenido duplicado
El contenido duplicado debe minimizarse en un sitio web, ya que puede dificultar que los motores de búsqueda decidan qué versión clasificar para una consulta.
Si bien una ‘penalización por contenido duplicado’ es un mito en SEO, el contenido muy similar puede causar ineficiencias en el rastreo, diluir el PageRank y ser una señal de contenido que podría consolidarse, eliminarse o mejorarse.
Vale la pena recordar que el contenido duplicado y similar es una parte natural de la web, lo que a menudo no es un problema para los motores de búsqueda que, por diseño, canonicalizarán las URL y las filtrarán cuando corresponda. Sin embargo, a escala puede ser más problemático.
Prevención de contenido duplicado
Le permite controlar lo que se indexa y clasifica, en lugar de dejarlo en manos de los motores de búsqueda. Puede limitar el desperdicio de presupuesto de rastreo y consolidar la indexación y las señales de enlace para ayudar en la clasificación.
Este tutorial lo guía a través de cómo puede usar Screaming Frog para encontrar tanto contenido duplicado exacto como contenido casi duplicado donde algún texto coincide entre las páginas de un sitio web.
El contenido duplicado identificado por cualquier herramienta, incluido SEO Spider, debe revisarse en contexto. Mire nuestro video o continúe leyendo nuestra guía a continuación.
Para comenzar, descargue Screaming Frog que es gratuito para rastrear hasta 500 URL. Los primeros 2 pasos solo están disponibles con un licencia. Si es un usuario gratuito, salte a numero 3 en la guía.
1) Habilite ‘Cerca de duplicados’ a través de ‘Configuración> Contenido> Duplicados’
Por defecto, SEO Spider identificará automáticamente las páginas duplicadas exactas. Sin embargo, para identificar ‘Casi Duplicados’ la configuración debe estar habilitada, lo que le permite almacenar el contenido de cada página.
SEO Spider identificará casi duplicados con una coincidencia de similitud del 90%, que se puede ajustar para encontrar contenido con un umbral de similitud más bajo.

SEO Spider también solo verificará las páginas ‘Indexables’ en busca de duplicados (tanto para duplicados exactos como casi duplicados).
Esto significa que si tiene dos URL que son iguales, pero una está canonicalizada para la otra (y, por lo tanto, «no indexable»), esto no se informará, a menos que esta opción esté deshabilitada.
Si está interesado en encontrar problemas de presupuesto de rastreo, desmarque la opción ‘Solo verificar páginas indexables para duplicados’, ya que esto puede ayudar a encontrar áreas de posible desperdicio de rastreo.
2) Ajuste el ‘Área de contenido’ para el análisis a través de ‘Configuración> Contenido> Área’
Puede configurar el contenido utilizado para el análisis casi duplicado. Para un nuevo rastreo, recomendamos usar la configuración predeterminada y refinarla más tarde cuando se pueda ver y considerar el contenido utilizado en el análisis.
SEO Spider excluirá automáticamente los elementos de navegación y pie de página para centrarse en el contenido del cuerpo principal. Sin embargo, no todos los sitios web se construyen con estos elementos HTML5, por lo que puede refinar el área de contenido utilizada para el análisis si es necesario. Puede elegir ‘incluir’ o ‘excluir’ etiquetas HTML, clases e ID en el análisis.
Por ejemplo, el sitio web de Screaming Frog tiene un menú móvil fuera del elemento de navegación, que se incluye en el análisis de contenido de forma predeterminada. Si bien esto no es un gran problema, en este caso, para ayudar a enfocarse en el texto del cuerpo principal de la página, su nombre de clase ‘mobile-menu__dropdown’ se puede ingresar en el cuadro ‘Excluir clases’.

Esto excluirá el menú de ser incluido en el algoritmo de análisis de contenido duplicado. Más sobre esto más adelante.
3) Rastrear el sitio web
Abra SEO Spider, escriba o copie el sitio web que desea rastrear en el cuadro ‘Enter URL to spider’ y presione ‘Iniciar’.
Espere hasta que finalice el rastreo y alcance el 100%, pero también puede ver algunos detalles en tiempo real.
4) Ver duplicados en la pestaña ‘Contenido’
La pestaña Contenido tiene 2 filtros relacionados con el contenido duplicado, ‘duplicados exactos’ y ‘casi duplicados’.

Solo los «duplicados exactos» están disponibles para ver en tiempo real durante un rastreo. ‘Casi duplicados’ requiere un cálculo al final del rastreo a través de la publicación ‘Análisis de rastreo’ para que se complete con datos.
El panel «descripción general» de la derecha muestra el mensaje «(Análisis de rastreo requerido)» contra los filtros que requieren un análisis posterior al rastreo para completarse con datos.
5) Haga clic en ‘Análisis de rastreo > Iniciar’ para completar el filtro ‘Cerca de duplicados’
Para completar el filtro ‘Cerca de duplicados’, la ‘Coincidencia de similitud más cercana’ y ‘No. Cerca de las columnas de Duplicados, solo necesita hacer clic en un botón al final del rastreo.
Sin embargo, si configuró ‘Análisis de rastreo’ anteriormente, es posible que desee volver a verificar, en ‘Análisis de rastreo> Configurar’, que está marcado ‘Cerca de duplicados’.
También puede desmarcar otros elementos que también requieren un análisis posterior al rastreo para que este paso sea más rápido.
Cuando el análisis de rastreo se haya completado, la barra de progreso de ‘análisis’ estará al 100 % y los filtros ya no tendrán el mensaje ‘(Análisis de rastreo requerido)’.
Ahora puede ver las columnas y el filtro casi duplicado rellenados.
6) Ver la pestaña ‘Contenido’ y los filtros de duplicados ‘Exacto’ y ‘Cerca’
Después de realizar un análisis posterior al rastreo, el filtro ‘Cerca de duplicados’, la ‘Coincidencia de similitud más cercana’ y ‘No. Se completarán las columnas de Near Duplicates. Solo las URL con contenido por encima del umbral de similitud seleccionado contendrán datos, las demás permanecerán en blanco. En este caso, el sitio web de Screaming Frog tiene solo dos.
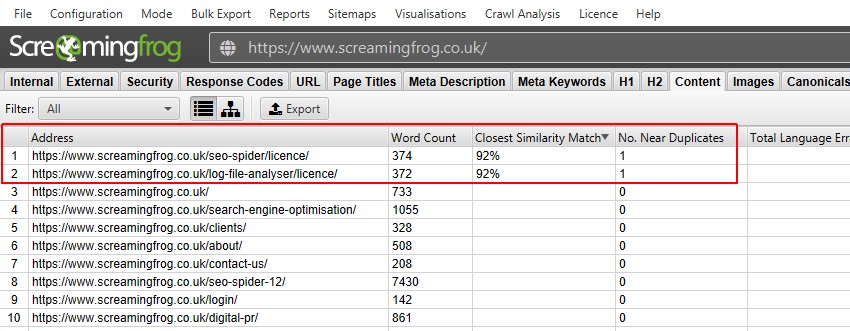
Un rastreo de un sitio web más grande, como la BBC, revelará muchos más.

Filtros disponibles
- Duplicados exactos – Este filtro mostrará páginas que son idénticas entre sí usando el algoritmo MD5 que calcula un valor ‘hash’ para cada página y se puede ver en la columna ‘hash’. Esta verificación se realiza contra el HTML completo de la página. Mostrará todas las páginas con valores hash coincidentes que sean exactamente iguales. Las páginas duplicadas exactas pueden provocar la división de las señales de PageRank y la imprevisibilidad en la clasificación. Solo debe haber una única versión canónica de una URL que exista y esté vinculada internamente. No se deben vincular otras versiones y se deben redirigir 301 a la versión canónica.
- Cerca de duplicados – Este filtro mostrará páginas similares según el umbral de similitud configurado utilizando el algoritmo minhash. El umbral se puede ajustar en ‘Configuración > Spider > Contenido’ y está establecido en 90 % de manera predeterminada. La columna «Coincidencia de similitud más cercana» muestra el porcentaje más alto de similitud con otra página. El no. La columna Near Duplicates muestra el número de páginas que son similares a la página según el umbral de similitud. El algoritmo se ejecuta contra el texto de la página, en lugar del HTML completo como duplicados exactos. El contenido utilizado para este análisis se puede configurar en ‘Configuración > Contenido > Área’. Las páginas pueden tener una similitud del 100%, pero solo ser un ‘casi duplicado’ en lugar de un duplicado exacto. Esto se debe a que los duplicados exactos se excluyen como casi duplicados, para evitar que se marquen dos veces. Las puntuaciones de similitud también se redondean, por lo que el 99,5 % o superior se mostrará como 100 %.
Las páginas casi duplicadas deben revisarse manualmente, ya que existen muchas razones legítimas para que algunas páginas tengan un contenido muy similar, como variaciones de productos que tienen un volumen de búsqueda en torno a su atributo específico.
Sin embargo, las URL marcadas como casi duplicadas deben revisarse para considerar si deben existir como páginas separadas debido a su valor único para el usuario, o si deben eliminarse, consolidarse o mejorarse para que el contenido sea más profundo y único.
7) Ver URL duplicadas a través de la pestaña ‘Detalles duplicados’
Para los ‘duplicados exactos’, es más fácil verlos en la ventana superior usando el filtro, ya que están agrupados y comparten el mismo valor ‘hash’.
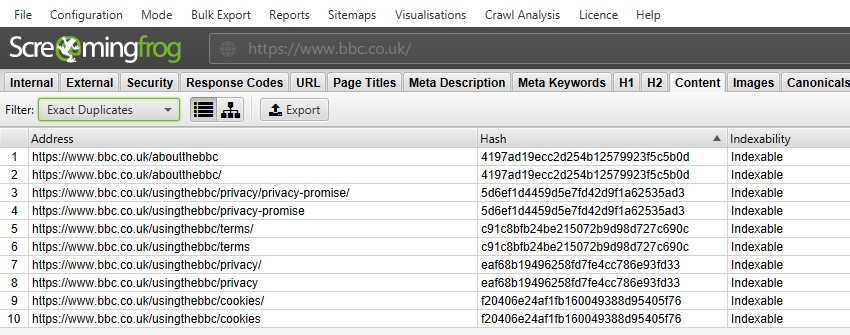
En la captura de pantalla anterior, cada URL tiene un duplicado exacto correspondiente debido a una barra inclinada final y una barra inclinada no final.
Para ‘casi duplicados’, haga clic en la pestaña ‘Detalles de duplicados’ en la parte inferior que llena el panel inferior de la ventana con la ‘dirección casi duplicada’ y la similitud de cada URL casi duplicada descubierta.
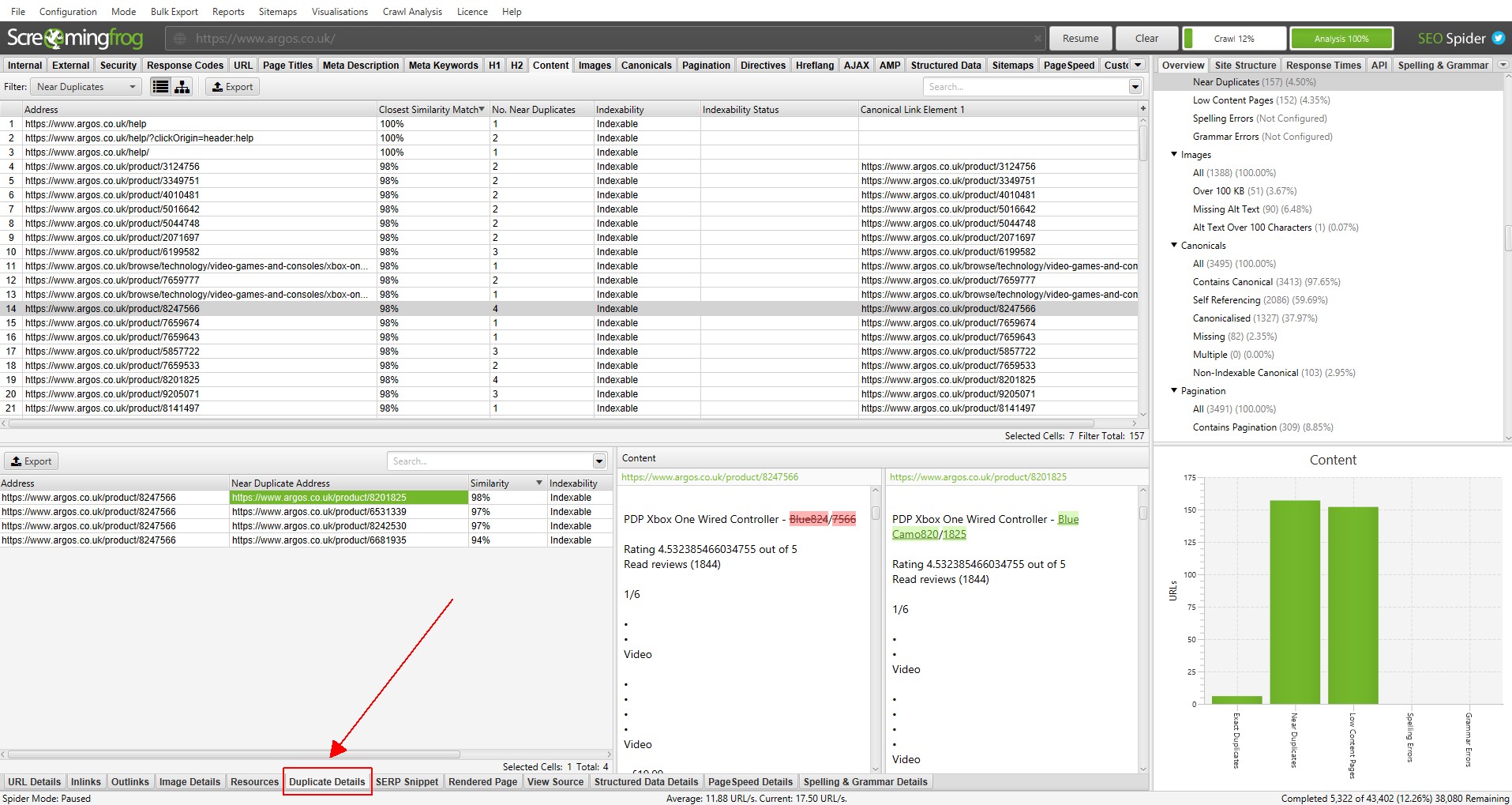
Por ejemplo, si se descubren 4 casi duplicados para una URL en la ventana superior, se pueden ver todos.

El lado derecho de la pestaña ‘Detalles duplicados’ mostrará el contenido casi duplicado descubierto en las páginas y resaltará las diferencias entre las páginas al hacer clic en cada ‘dirección casi duplicada’.

Si hay contenido duplicado en la pestaña de detalles duplicados que no desea que forme parte del análisis de contenido duplicado, excluya o incluya cualquier elemento HTML, clase o ID (como se destaca en punto 2) y vuelva a ejecutar el análisis de rastreo.
8) Duplicados de exportación masiva
Tanto los duplicados exactos como los casi duplicados se pueden exportar de forma masiva a través de las exportaciones ‘Exportación masiva > Contenido > Duplicados exactos’ y ‘Casi duplicados’.

¡Consejo final!
Refine el umbral de similitud y el área de contenido, y vuelva a ejecutar el análisis de rastreo
Después del rastreo, puede ajustar tanto el umbral de similitud de casi duplicados como el área de contenido utilizada para el análisis de casi duplicados.
A continuación, puede volver a ejecutar el análisis de rastreo para encontrar contenido más o menos similar, sin volver a rastrear el sitio web.

Como se indicó anteriormente, el sitio web de Screaming Frog tiene un menú móvil fuera del elemento de navegación, que se incluye en el análisis de contenido de forma predeterminada. El menú móvil se puede ver en la vista previa de contenido de la pestaña ‘detalles duplicados’.

Al excluir ‘mobile-menu__dropdown’ en el cuadro ‘Excluir clases’ en ‘Configuración > Contenido > Área’, el menú móvil se elimina de la vista previa de contenido y del análisis casi duplicado.

Esto realmente puede ayudar cuando se ajusta la identificación de contenido casi duplicado en áreas de contenido principal, sin necesidad de volver a rastrear.
Resumen
La guía anterior debería ilustrar cómo usar SEO Spider como un verificador de contenido duplicado para su sitio web. Para obtener los resultados más precisos, refine el área de contenido para el análisis y ajuste el umbral para diferentes grupos de páginas.
Para saber algo más, consulta la guía definitiva de Screaming Frog