
Cómo auditar el atributo rel canonical utilizando Screaming Frog
El elemento rel=”canonical” ayuda a especificar una única versión preferida de una página cuando está disponible a través de varias URL. Es una sugerencia para los motores de búsqueda para ayudar a prevenir el contenido duplicado, al consolidar la indexación y las propiedades de enlace en una sola URL para usar en la clasificación.
Este tutorial lo guía a través de cómo puede usar Screaming Frog para auditar la implementación canónica de manera rápida y eficiente en un sitio web. Screaming Frog rastreará los elementos de enlace canónicos que se encuentran en los encabezados HTML y HTTP e informará sobre su configuración y errores comunes.
Para comenzar, deberá descargar Screaming Frog que es gratis en formato lite, para rastrear hasta 500 URL. Puede descargar a través de los botones en la barra lateral derecha. A continuación, simplemente siga estos pasos.
1) Asegúrese de que las etiquetas canonicals se pueden ‘Almacenar’ y ‘Rastrear’ en ‘Configuración> Araña> Rastrear’
Esta opción está habilitada de forma predeterminada, por lo que, a menos que haya ajustado la configuración, ya estará configurada. La ‘Configuración’ de Screaming Frog está disponible en el menú de nivel superior.
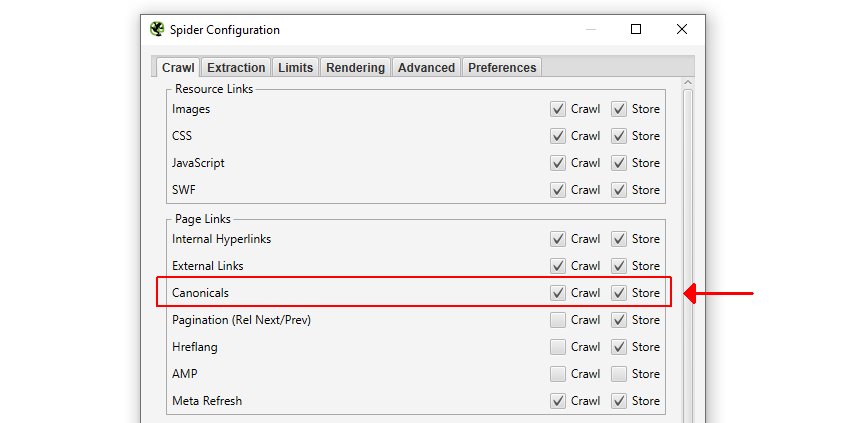
Esto significará que las URL a las que se hace referencia en rel=”canonical” serán rastreadas, extraídas e informadas. A continuación, haga clic en ‘Aceptar’.
2) Rastrear el sitio web
Abra Screaming Frog, escriba o copie el sitio web que desea rastrear en el cuadro ‘Enter URL to spider’ y presione ‘Iniciar’.
Se rastreará el sitio web y cualquier URL dentro de los elementos rel=”canonical”.
Ahora tome un café y espere hasta que la barra de progreso alcance el 100% y el rastreo se complete.
3) Ver la pestaña Canonicals
En la pestaña Canonicals se muestran todas las URL encontradas en un rastreo y sus correspondientes elementos de enlace rel=”canonical” y HTTP Canonicals en columnas separadas correspondientes en el panel de la ventana principal.
La pestaña canonicals tiene 6 filtros que lo ayudan a comprender su implementación canónica e identificar problemas canónicos comunes.
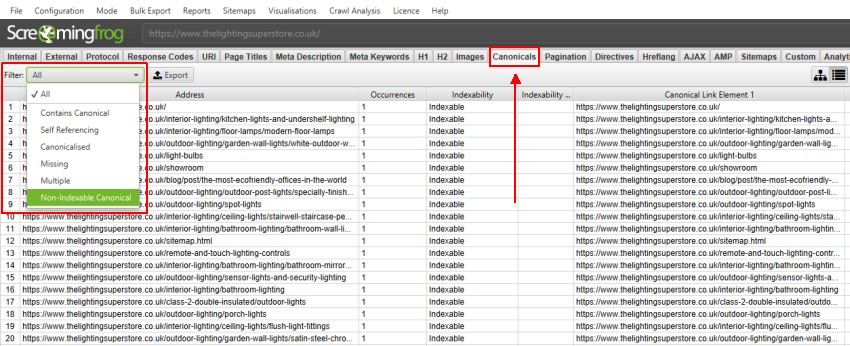
La columna ‘Ocurrencias’ cuenta el número de elementos rel=”canonical” que se han descubierto para cada URL.
El panel de la ventana de descripción general de la derecha proporciona un resumen de los datos contenidos en cada pestaña y filtro, para que sepa dónde hacer clic, sin tener que revisar cada filtro para ver si hay datos. En la imagen a continuación, podemos ver que hay 1 URL que está ‘canonicalizada’ y 1 URL que tiene un ‘canónico no indexable’.

Puede filtrar por lo siguiente:
- Contiene Canónico – La página tiene un conjunto de URL canónico (ya sea a través de un elemento de enlace, un encabezado HTTP o ambos). Esta podría ser una URL canónica autorreferenciada donde la URL de la página es la misma que la URL canónica, o podría ser «canónica», donde la URL canónica es diferente a la URL de la página.
- Autorreferencia – La URL tiene un canónico que es la misma URL que la URL de la página rastreada (por lo tanto, es autorreferencial). Idealmente, solo las versiones canónicas de las URL estarían vinculadas internamente, y cada URL tendría una referencia canónica a sí misma para ayudar a evitar cualquier posible problema de contenido duplicado que pueda ocurrir (incluso de forma natural en la web, como el seguimiento de parámetros en las URL, otros sitios web incorrectamente). vinculando a una URL que resuelve, etc.).
- canonicalizado – La página tiene una URL canónica diferente a ella misma. La URL se ‘canonicaliza’ a otra ubicación. Esto significa que se indica a los motores de búsqueda que no indexen la página, y las propiedades de indexación y vinculación deben consolidarse en la URL canónica de destino. Estas URL deben revisarse cuidadosamente. En un mundo perfecto, un sitio web no necesitaría canonicalizar ninguna URL, ya que solo se vincularían las versiones canónicas, pero a menudo son necesarias debido a diversas circunstancias fuera de control y para evitar contenido duplicado.
- Perdido – No hay una URL canónica presente como un elemento de enlace o a través del encabezado HTTP. Si una página no indica una URL canónica, Google identificará lo que cree que es la mejor versión o URL. Esto puede conducir a una clasificación impredecible y, por lo tanto, en general, todas las URL deben especificar una versión canónica.
- Múltiple – Hay varios canónicos establecidos para una URL (ya sean elementos de enlace múltiples, encabezado HTTP o ambos combinados). Esto puede generar imprevisibilidad, ya que solo debe haber una única URL canónica establecida por una sola implementación (elemento de enlace o encabezado HTTP) para una página.
- Canónico no indexable – La URL canónica es una página no indexable. Esto incluirá canónicos que están bloqueados por robots.txt, sin respuesta, redireccionamiento (3XX), error del cliente (4XX), error del servidor (5XX) o son ‘noindex’. Las versiones canónicas de las URL siempre deben ser páginas de respuesta ‘200’ indexables. Por lo tanto, los canónicos que van a páginas no indexables deben corregirse a las versiones indexables de resolución.
4) Ver URL canónicas no indexables ‘Estado de indexabilidad’ a través de la pestaña ‘Información de URL’ del panel inferior de la ventana
La pestaña ‘Información de URL’ en la parte inferior muestra la razón por la cual un canónico no es indexable. Según el ejemplo a continuación, esta URL canónica no es indexable porque se redirige.

La URL canónica es ‘https://www.thelightingsuperstore.co.uk/clearance-lighting/clearance-stock-light-fittings’, que redirige. Por lo tanto, esto se considera como ‘no indexable’.
5) Utilice la exportación ‘Informes > Canónicos > Canónicos no indexables’ a URL de origen de exportación masiva, URL canónicos no indexables y sus códigos de estado
Para exportar de forma masiva los detalles de las páginas de origen que contienen canónicos no indexables, su respectiva indexabilidad, estado de indexabilidad, estado y código de estado, haga clic en ‘informes’ en el menú de nivel superior y seleccione ‘Canónicos > Canónicos no indexables’.
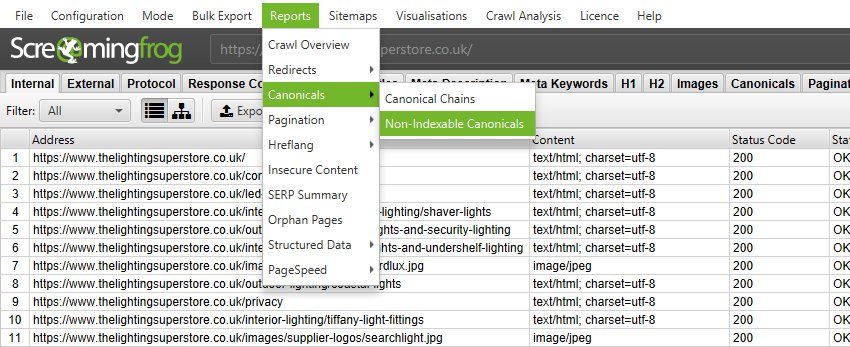
Esta exportación a menudo es mucho más fácil de digerir y trabajar para solucionarla (o enviarla a un desarrollador para que la solucione). También incluye detalles de cualquier URL canónica que esté ‘desvinculada’ en el rastreo, a través de elementos de anclaje HTML normales.
6) Haga clic en el informe ‘Informes > Canónicos > Cadenas canónicas’ para ver los bucles y canónicos encadenados
Al igual que los redireccionamientos, los canónicos también se pueden encadenar y tener bucles. La URL de una página se puede canonizar a otra URL, que se canoniza a otra URL y así sucesivamente. O, a menudo, una combinación de canónicos y redireccionamientos juntos.

Una vez que se haya exportado este informe, filtre la columna ‘Tipo de cadena’ para ‘Canónica’ o ‘Mixta’ para ver las cadenas canónicas. En el ejemplo anterior, podemos ver que hay un bucle de redirección ‘mixto’, debido a la URL canónica no indexable.
La siguiente imagen muestra la hoja de cálculo exportada, que muestra que hay dos ‘redireccionamientos’ (que en realidad significa ‘saltos’, ya que puede incluir URL canonicalizadas), la ‘dirección’ de inicio y la ‘dirección final’ en columnas fijas. La indexabilidad de la dirección final es ‘no indexable’, ya que está ‘canonicalizada’. Haga clic en la imagen para ampliar.
![]()
Desplazándose a la derecha de la hoja de cálculo, se muestran cada uno de los saltos que se han descubierto. Podemos ver que la dirección tiene una redirección canónica con un código de estado 301, que vuelve a la URL de inicio (provocando un bucle). Nuevamente, puede hacer clic en la imagen para expandirla.
![]()
Para resumir la hoja de cálculo, la exportación de cadenas canónicas muestra que la página https://www.thelightingsuperstore.co.uk/clearance-lighting tiene una URL canónica configurada como https://www.thelightingsuperstore.co.uk/clearance-lighting/ liquidacion-stock-luminarias.
Sin embargo, la URL canónica https://www.thelightingsuperstore.co.uk/clearance-lighting/clearance-stock-light-fittings en realidad redirige 301 al original https://www.thelightingsuperstore.co.uk/clearance-lighting página principal.
Si bien esto no es un gran problema, es una señal contradictoria para los motores de búsqueda y debe corregirse. Puede haber algunos escenarios en los que las cadenas canónicas sean mucho más grandes y más complicadas, y este informe ayudará a identificar y resaltar el error y la ruta completa en la cadena.
Resumen
La guía anterior debería ayudar a ilustrar los sencillos pasos necesarios para auditar rel=”canonical” en un sitio web utilizando Screaming Frog